
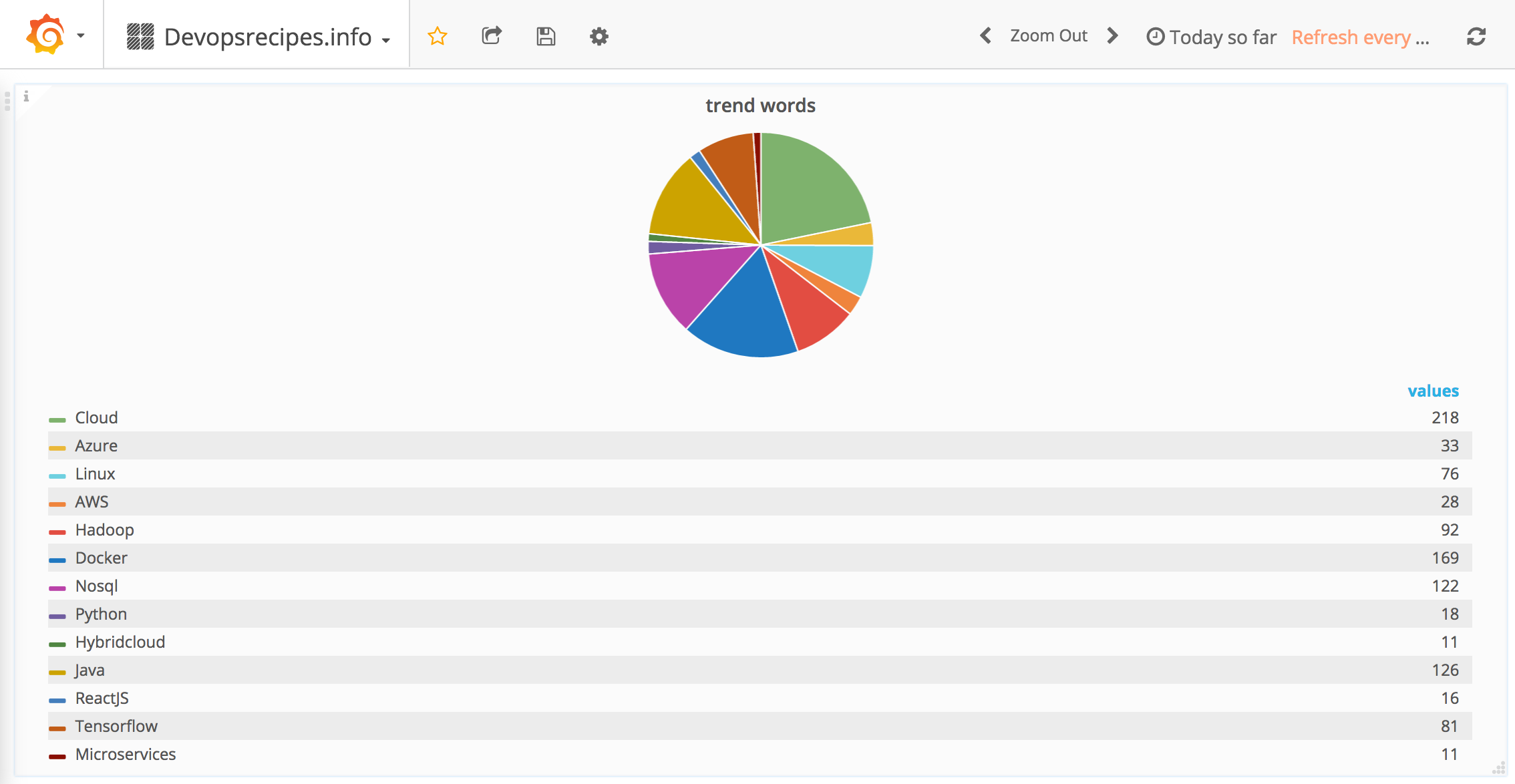
Devops trends from MongoDB, Grafana and spammed mailbox. Update #1
Hi all! this is the first update from my new Big data experimental project… How can I be updated with devops trend technologies without reading tons of blog? I started to…
Hi all! this is the first update from my new Big data experimental project… How can I be updated with devops trend technologies without reading tons of blog? I started to…
Hi everybody! my task of today, was to configure a MongoDB with redundancy and high availability… I decided to write my own Chef cookbook to configure “replica” Below the most important…