Come è nata l’idea
Ciao, sono Federico Martellini e il primo incarico ricevuto dalla Tribe consisteva nell’apprendere e utilizzare il linguaggio di programmazione Go di Google.
E’ stata la prima volta che sono entrato in contatto con questo linguaggio e per analizzarlo sono partito dalla mia formazione universitaria di programmazione e sviluppo in ambiente C/C++ in cui operavo solitamente.
Le caratteristiche di Go che mi hanno subito colpito sono state la sua semplicità/rapidità d’uso, il suo orientamento alla programmazione lato server e multiprocessing ( ovvero la gestione del parallelismo su architetture multi-processore).
Dovendomi quindi interfacciare con una nuova modalità di lavoro, e immaginando di dover probabilmente collaborare in futuro con colleghi nell’ambito di progetti basati su Go, ho sentito anche la necessità di individuare uno strumento di distribuzione e condivisione degli elaborati da produrre.
A chi è rivolto l’articolo
Questo articolo è quindi rivolto a chi si avvicina a Go avendo uno scarso o nullo livello di conoscenza del linguaggio, ed ha l’obiettivo pragmatico di portare il lettore alla creazione delle prime applicazioni, attraverso un approccio semplice e rapido e soprattutto con l’obiettivo logico di porlo in condizione di apprezzare le migliori caratteristiche di GoLang.
Essendo stato anche io un neofita del linguaggio, ho pensato di utilizzare per questo articolo la descrizione del walktrough di apprendimento che ho personalmente seguito.
Per questo motivo penso sia utile includere anche la descrizione dei problemi incontrati e la logica di decisione delle scelte operate.
Walktrough di apprendimento
Caratteristiche generali di GoLang
GoLang è identificato come un linguaggio di programmazione open-source rilasciato nel 2009 la cui struttura è legata a quella di C/C++ e Assembly, ma è dotato anche di strumenti necessari per la realizzazione di applicazioni web, micro-servizi e sistemi distribuiti.
Le sue caratteristiche generali che mi hanno maggiormente colpito sono le seguenti:
- La filosofia del linguaggio Go punta alla pulizia, semplicità, praticità e chiarezza di scrittura: ha solo 25 parole chiave
- Controllo a runtime dell’allocazione/deallocazione di stringhe, array, puntatori
- Sono disponibili i compilatori per i sistemi operativi: Unix (incluso macOS), Linux, Windows e supportano diverse architetture HW
- Il binario eseguibile prodotto dal compilatore Go contiene tutte le librerie utilizzate e quindi può essere distribuito autonomamente
- Esistono numerose librerie standard di uso comune
- Possono essere integrate librerie scritte in C
- Come già riportato, Go è orientato alla programmazione lato server e al multi-processing
- Compila nativamente in codice macchina: non serve una virtual machine o interprete. Si ha di conseguenza un immediato vantaggio in termini di velocità ed efficienza
Riguardo alle caratteristiche di Go pensate per facilitare il processo di scrittura del programmatore riporto i seguenti punti. Magari fossero esistite in C ai tempi dello studio!
- Gestione della memoria impiegata (“safe memory language”)
- ll linguaggio vieta di importare librerie se all’interno del codice non è richiamato alcun costrutto appartenente ad esse
- Diversamente da C/C++, in cui ad una variabile non espressamente inizializzata è assegnato un valore qualunque, Go assegna un valore di default fisso dipendente dal tipo ad ogni variabile non inizializzata (e.g. 0 per un valore intero o nil per un puntatore). Tale caratteristica assume maggior valore quando si utilizzano i puntatori
- Semplicità e flessibilità della sintassi
- Le istruzioni non richiedono uno specifico carattere per determinarne la fine (e. g. ‘;’ in C/C++), questo viene dedotto automaticamente
- Il tipo di una variabile può essere definito in fase di assegnazione di un valore (e.g. l’assegnazione a:=2 forza il tipo int per la variabile a; l’assegnazione b:=3.14 forza il tipo float per la variabile b)
- Il codice Go si presenta in forma più “snella e leggera” e, oltre ad essere meno soggetto ad errori di scrittura, risulta molto più scorrevole nella lettura e interpretazione.
Selezione approccio complessivo
Ho già accennato di aver utilizzato volutamente un approccio pragmatico che punta ad un uso rapido ma efficace del linguaggio, senza entrare nel dettaglio profondo del linguaggio stesso.
Attività di studio eseguite
Il primo step ritenuto necessario è stata la selezione di un editor che supportasse al meglio la scrittura del codice Go.
Selezione editor
I parametri che hanno indirizzato la scelta dell’editor sono stati nell’ordine d’importanza:
- Capacità di evidenziare la sintassi del linguaggio Go
- Compatibile con Windows, Linux
- Integrazione con Git
- Capacità IntelliSense (completamento automatico delle istruzioni)
- Capacità d’integrazione del supporto per il debugging
Ho scelto VSCode (Visual Studio Code), distribuito da Microsoft come OpenSource.
Da notare che la capacità cross platform di VSCode non vincola da subito la scelta del OS da utilizzare.
Tale scelta è dovuta a considerazioni di tipo complessivo relative all’intero workspace come verrà chiarito successivamente.
A scopo di verifica ho provveduto ad installare l’editor sia su Windows 10 (@Eugenio scusa) che su Linux CentOs 8.2 che avevo entrambe disponibili nel mio precedente ambiente di studio/lavoro.
Le procedure di download e d’installazione su piattaforma Windows 10 e sono disponibili alla pagina del sito ufficiale di VSCode.
La procedura per CentOS che ho utilizzato, è invece riportata di seguito:
1. Aggiornamento della distribuzione (se necessario)
sudo dnf -y update2. Import del repository Microsoft relativo a VSCode.
sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc3. Aggiunta del repository stesso.
cat <<EOF | sudo tee /etc/yum.repos.d/vscode.repo
[code]
name=Visual Studio Code
baseurl=https://packages.microsoft.com/yumrepos/vscode
enabled=1
gpgcheck=1
gpgkey=https://packages.microsoft.com/keys/microsoft.asc
EOF4. Verifica aggiornamenti repository di VSCode.
sudo dnf check-update5. Installazione VSCode.
$ sudo dnf install codeInstallazione di Go
Non avendo ancora selezionato definitivamente la piattaforma su cui lavorare, ho deciso di installarlo sia su Windows che su Linux.
Entrambe le versioni sono scaricabili dal sito:
La versione GoLang utilizzata è la 1.20.5.
Installazione su Windows 10 Pro vers. 22H2
Seguendo le istruzioni del sito GoLang, ho scaricato il file
go1.20.5.windows-amd64.msi.
“Cliccato” poi sul file è partita l’installazione automatica utilizzando i default presentati (e.g. directory di installazione C:\Program Files\Go\).
Al termine dell’operazione ho verificato la versione installata digitando il comando
$ go versionall’interno di una finestra del prompt dei comandi.
Installazione su Linux CentOS 8.2
Per installare GoLang in Linux è necessario utilizzare il package wget che permette di recuperare file da Internet utilizzando I protocolli HTTP, HTTPS, FTP e FTPS (vedi maggiori informazioni sul sito https://www.gnu.org/software/wget/ ).
Vanno eseguiti quindi i seguenti passaggi utilizzando un terminale:
1. Installazione pacchetto wget.
$ Sudo yum -y install wget2. Utilizzare wget per scaricare il file d’installazione di GoLang.
$ wget https://storage.googleapis.com/golang/getgo/installer_linux3. Rendere eseguibile il file d’installazione.
$ chmod +x ./installer_linux4. Eseguire l’installazione.
$ ./installer_linux5. Al termine dell’installazione aggiornare il profilo dell’utente perché modificato dall’installazione stessa.
$ source ~/.bash_profile6. In fine verificare la versione di GoLang installata.
$ go versionFamiliarizzazione con GoLang
In generale per famigliarizzare con un qualsiasi strumento è maggiormente utile utlizzare esempi e tutorial messi a disposizione dalla società creatrice dello strumento stesso.
Anche nel mio caso ho iniziato utilizzando i tutorial generati da Google, il cui primo step si può trovare nel sito sotto riportato:
Per comodità del lettore ho riportato la prima scheda del tutorial.
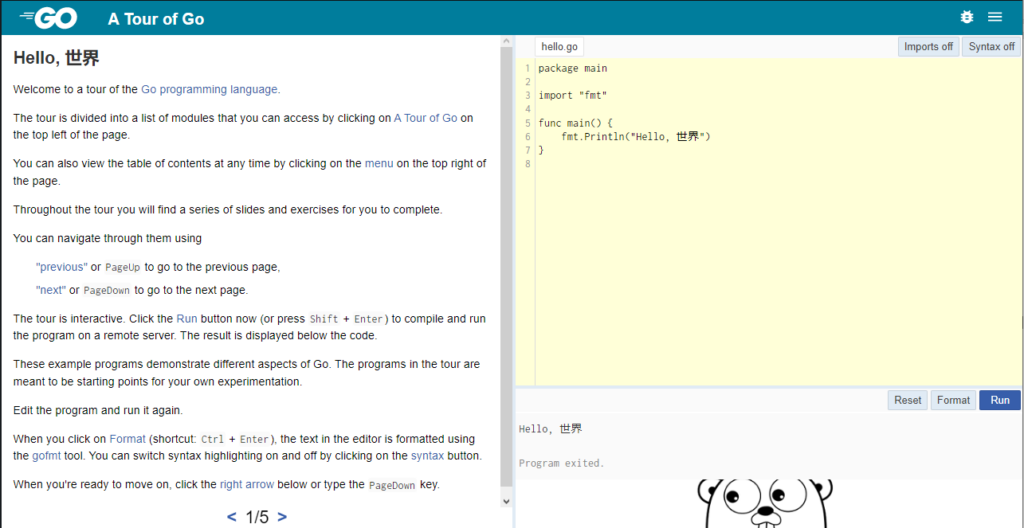
Come è facile vedere, questo tutorial genera una singola pagina web (fullscreen non scrollabile) per ogni singolo argomento trattato.
Questa pagina è divisa in due blocchi: a sinistra vengono descritti il contesto e alcuni dettagli dell’istruzione o costrutto trattato; nel blocco di destra, nella parte superiore è postato il codice di esempio applicativo del costrutto trattato, che è editabile e permette all’utente di sperimentare varianti dell’esempio fornito. Nella parte inferiore sono riportati i risultati dell’esecuzione del codice di esempio.
Sempre nel blocco di destra l’utente ha a disposizione 3 tasti che permettono nell’ordine:
- Tasto Reset – ripristina il codice di esempio originale se l’utente avesse necessità di eliminare le modifiche apportate.
- Tasto Format – richiama una proprietà di GoLang che automaticamente indenta il codice di esempio.
- Tasto Run – esegue il codice di esempio e visualizza in basso l’output generato.
La lista degli argomenti trattati dal tutorial utilizzato è estesa, ma mi pare utile riportarla di seguito per avere uno sguardo d’inseme degli argomenti trattati.
- Sommario
- Hello, 世界
- The Go Playground
- Packages, variables, and functions
- Packages
- Imports
- Exported names
- Funcfions
- Functions continued
- Multiple results
- Named return values
- Variables
- Short variable declarations
- Basic types
- Zero values
- Type conversions
- Type inference
- Constants
- Numeric Constants
- Flow control statements: for, if, else, switch and defer
- For
- For confinued
- For is Go’s “while”
- Forever
- If
- If with a short statement
- If and else
- Exercise: Loops and Functions
- Switch
- Switch evaluation order
- Switch with no condition
- Defer
- Stacking defers
- More types: structs, slices, and maps
- Pointers
- Structs
- Struct Fields
- Pointers to structs
- Struct Literals
- Arrays
- Slices
- Slices are like references to arrays
- Slice literals
- Slice defaults
- Slice length and capacity
- Nil slices
- Slices of slices
- Appending to a slice
- Range
- Range continued
- Exercise: Slices
- Maps
- Map literals
- Map literals continued
- Mutatmg Maps
- Exercise: Maps
- Function values
- Function closures
- Exercise: Fibonacci closure
- Methods and interfaces
- Methods
- Methods are functions
- Methods continued
- Pointer receivers
- Pointers and functions
- Methods and pointer indirection
- Methods and pointer indirection ()
- Choosing a value or pointer receiver
- Interfaces
- Interfaces are implemented implicitly
- Interface values
- Interface values with nil underlying values
- Nil interface values
- The empty interface
- Type assertions
- Type switches
- Stringers
- Exercise: Stringers
- Errors
- Exercise: Errors
- Readers
- Exercise: Readers
- Exercise: rotReader
- Images
- Exercise: Images
- Generics
- Type parameters
- Generic types
- Concurrency
- Goroutines
- Channels
- Buffered Channels
- Range and Close
- Select
- Default Selection
- Exercise: Equivalent Binary Trees
- sync.Mutex
Con i dovuti ringraziamenti a chi ha prodotto gratuitamente questo tutorial, vorrei riportare alcune criticità che ho riscontrato.
- Ogni esempio è strettamente circoscritto alla specifica nozione illustrata: quindi non risulta di facile assimilazione la logica complessiva di utilizzo della nozione stessa.
- La grande libertà di implementazione di alcuni costrutti (e.g. ciclo for) mostrata nel corso del tutorial, fa sì che questo sia di natura enciclopedica e quindi non suggerisce alcuna best-practice da poter usare nel mondo lavorativo (su questo tema tornerò prossimamente approfondendo con qualche libro e prendendo spunto di progetti open-source maturi)
In conclusione confermo di aver utilizzato, in fase di familiarizzazione, tutto il tutorial ma devo aggiungere che in alcuni casi ho ritenuto necessario verificare la logica di alcuni costrutti eseguendo una “traduzione” di qualche codice precedentemente scritto in C/C++ in GoLang.
Riporto di seguito alcuni esempi di sorgenti in C/C++ e delle corrispondenti versioni in GoLang.
Caso 1: Rilevatore di parole palindrome
Versione C/C++
#include<stdio.h>
#include<string.h>
#define MAX_DIM 100
int main()
{
char stringa[MAX_DIM];
int contatore=0, i, quanti=0 ;
scanf("%s“,stringa);
contatore=strlen(stringa)-1;
for(i=0;i<contatore/2;i++)
if(stringa[i]==stringa[contatore-i]) quanti++;
if(quanti==contatore/2) printf(“Palindromo”);
else printf(“Non Palindromo”);
return 0;
} Versione GoLang
package main
import (
"fmt"
"strings"
)
func main() {
var stringa string
fmt.Scan(&stringa)
contatore := len(stringa) - 1
quanti := 0
for i := 0; i < contatore/2; i++ {
if stringa[i] == stringa[contatore-i] {
quanti++
}
}
if quanti == contatore/2 {
fmt.Println("Palindromo")
} else {
fmt.Println("Non Palindromo")
}
}Caso 2: Gestione di array di stringhe
Versione C/C++
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#define MAX_LENGTH 100
#define NUM_STRINGS 10
int main(){
char *arr3[NUM_STRINGS] = { "first string",
"second string",
"third string",
"fourth string",
"fifth string" };
char* str1 = "string literal";
arr3[8] = str1;
arr3[9] = "hello there";
for (int i = 0; i < NUM_STRINGS; ++i) {
printf("%s, ", arr3[i]);
}
printf("\n");
exit(EXIT_SUCCESS);
}Versione GoLang
package main
import (
"fmt"
)
const (
MAX_LENGTH = 100
NUM_STRINGS = 10
)
func main() {
arr3 := [NUM_STRINGS]*string{
"first string",
"second string",
"third string",
"fourth string",
"fifth string",
}
str1 := "string literal"
arr3[8] = &str1
arr3[9] = new(string)
*arr3[9] = "hello there"
for i := 0; i < NUM_STRINGS; i++ {
fmt.Printf("%s, ", *arr3[i])
}
fmt.Println()
}Caso 3: Generatore di Slice
Versione C/C++
#include <iostream>
#include <vector>
void printSlice(const std::string& s, const std::vector<int>& x) {
std::cout << s << " len=" << x.size() << " cap=" << x.capacity() << " ";
for (const auto& element : x) {
std::cout << element << " ";
}
std::cout << std::endl;
}
int main() {
std::vector<int> a(5);
printSlice("a", a);
std::vector<int> b;
b.reserve(5);
printSlice("b", b);
std::vector<int> c(b.begin(), b.begin() + 2);
printSlice("c", c);
std::vector<int> d(c.begin() + 2, c.end());
printSlice("d", d);
return 0;
}Versione GoLang
package main
import "fmt"
func main() {
a := make([]int, 5)
printSlice("a", a)
b := make([]int, 0, 5)
printSlice("b", b)
c := b[:2]
printSlice("c", c)
d := c[2:5]
printSlice("d", d)
}
func printSlice(s string, x []int) {
fmt.Printf("%s len=%d cap=%d %v\n",
s, len(x), cap(x), x)
}
Caso 4: Gestione mappatura tra variabili
Versione C/C++
#include <iostream>
#include <map>
struct Vertex
{
double Lat;
double Long;
};
int main() {
std::map<std::string, Vertex> m;
m["Bell Labs"] = {40.68433, -74.39967};
std::cout << m["Bell Labs"].Lat << ", " << m["Bell Labs"].Long << std::endl;
return 0;
}Versione GoLang
package main
import "fmt"
type Vertex struct {
Lat, Long float64
}
var m map[string]Vertex
func main() {
m = make(map[string]Vertex)
m["Bell Labs"] = Vertex{
40.68433, -74.39967,
}
fmt.Println(m["Bell Labs"])
}“Lesson learned”
Al netto delle (ovvie) differenze grammaticali, la sintassi di GoLang è nei casi più semplici (vedi Casi 1,2) praticamente identica al C/C++. Nei casi in cui è necessario mappare le esigenze del programma con costrutti più complessi si deve fare immediatamente riferimento alle logiche proprie di GoLang (vedi Casi 3,4).
Ritengo utile suggerire una fase di apprendimento del tipo prima descritto.
Avendo raggiunto un utile anche se non profondo livello di conoscenza di GoLang, sono passato ad una fase di sperimentazione con l’obiettivo di verificare specifiche capacità fornite da GoLang.
In particolare le sezioni che seguono riportano brevi esempi di utilizzo appartenenti alle seguenti categorie :
- Programmi generali algoritmici stand-alone basati sull’uso di istruzioni e strutture del linguaggio
- Specifici programmi che utilizzano librerie GoLang
- Strumenti per la conservazione e distribuzione di prodotti sviluppati (anche) in GoLang
Esempio di programma stand-alone – Insieme di Mandelbrot
Ho deciso di scegliere l’implementazione dell’algoritmo frattale proposto da Mandelbrot.
In particolare si tratta di un insieme di numeri complessi , la cui successione è definita dalla seguente formula:
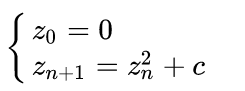
Questa successione ha una semplice definizione ma produce una forma il cui contorno è un frattale la cui complessità può essere rappresentata solo tramite visualizzazione di computer grafica.
Il carico computazionale dell’algoritmo associato è tale che può essere utiilzzato come un benchmark per misurare le capacità di macchine diverse. In particolare l’algoritmo ha due elementi chiave :
- Numero massimo di iterazioni per punto per determinare se il valore sul piano complesso appartenga o meno all’insieme di Mandelbrot
- Risoluzione pari al numero di punti che il programma deve elaborare tra due valori interi, ad esempio tra il punto 0+i0 e il punto 1+i0 possono essere elaborati 2500 punti.
L’area di ricerca è posta tra i limiti, sull’asse reale tra -2+i0 e 1+i0, mentre sull’asse complesso tra
1i e -1i.
Partendo da questi dati si calcola che l’immagine prodotta abbia larghezza pari a tre volte la risoluzione e altezza pari a due volte la risoluzione.
Il codice prodotto ha due funzionalità: implementazione dell’algoritmo e generazione delle immagini grafiche associate.
Avendo già utilizzato questo algoritmo per studi precedenti, ho recuperato una versione scritta in C che ho utilizzato come base per generare una versione in Go..
Va notato che la parte della conversione algoritmica è stata praticamente immediata e il codice GoLang prodotto risulta, a mio parere, più leggibile rispetto alla versione C. Al contrario, per quanto riguarda la conversione della sezione grafica ho incontrato alcuni problemi da risolvere.
In particolare, la versione in C utilizzava la libreria X11 che è ancora funzionante sulla distribuzione Rocky9; purtroppo non ho trovato disponibile per GoLang sulla stessa distribuzione una libreria X11 utilizzabile in modo da riuscire a convertire, in un “rapporto 1:1”, i comandi grafici utilizzati in C.
Ho trovato 2 possibili soluzioni alternative:
- “wrappare” le librerie C per renderle disponibili a Go
- utilizzare librerie native di Go, ma applicando una programmazione direttamente in OpenGL senza poter utilizzare dei framework grafici di supporto come FreeGLUT.
Ho escluso da subito la prima soluzione, volendo tenere conto della natura di benchmark di questo esempio; riguardo alla seconda ho trovato svariate librerie di terze parti aventi livelli diversi di complessità, non solo in termini di codifica ma anche di presenza di catene di dipendenze.
In ultima analisi ho deciso di utilizzare una libreria nativa di GoLang di facile utilizzo e plausibilmente di semplice architettura, reperita sul sito https://github.com/fogleman/gg.
Esiste però una limitazione rispetto alla versione originale del codice C, perché questo ad ogni iterazione produce un’immagine frattale presentata immediatamente su una finestra, mentre la versione in GoLang produce e memorizza una serie di immagini isolate.
Per mia soddisfazione personale, appena possibile, cercherò una diversa libreria grafica che risolva questo problema.
Di seguito è riportato il codice prodotto
/* MANDELBROT ZOOMER PICTURE SEQUENCE */
/* per compilare: "go build mandelbrot-picture.go" */
package main
import (
"github.com/fogleman/gg"
"fmt"
)
// NOTE: WIDTH e HEIGHT impostano le dimensioni della finestra //
// RESOLUTION aumenta la velocita del programma a discapito della risoluzione (inserire solo potenze del 2) //
const WIDTH = 512
const HEIGHT = 480
const RESOLUTION = 1
var dx, dy, ca, cb, za, zb, old_za, old_zb, mul_za, mul_zb, r float64
var col, offset int
var k int
func draw (minx, maxx, miny, maxy, max_iter, max_mod, scala,xa ,xb float64,dc*gg.Context) {
za := 0.
zb := 0.
ca := 0.
cb := 0.
dx := (maxx - minx) / WIDTH
dy := (maxy - miny) / HEIGHT
for y:=0; y<HEIGHT; y+=RESOLUTION {
cb = (miny + float64(y) * dy) * scala - xb
for x:=0 ; x<WIDTH ; x+=RESOLUTION {
ca = (minx + float64(x) * dx) * scala + xa
col = 0
za = ca
zb = cb
for {
old_za = za
mul_za = za*za
mul_zb = zb*zb
za = mul_za - mul_zb + ca
zb = old_za*zb*2 + cb
r = mul_za + mul_zb
col++
if r > max_mod {
break;
}
if float64(col) > max_iter {
col = 0;
break;
}
}
for i:=0 ; i<RESOLUTION ; i++ {
offset = (x << 2) + (WIDTH << 2) * (y+i)
for j:=0 ; j<RESOLUTION; j++ {
dc.SetRGB255(int(col)<<2,int(col)<<1,int(col)<<1)
dc.SetPixel (x, y)
}
}
}
}
}
func main() {
var minx,maxx,miny,maxy,max_mod,max_iter,vzoom,xa,xb,scala,q float64
var dc *gg.Context
k :=0
dc = gg.NewContext(WIDTH, HEIGHT)
vzoom = 1.1 /* velocita di zoom */
xa = -0.376900000058 /* punto complesso di zooming */
xb = -0.638691000021
q = 10 /* fattore di correzione per max_iter */
max_iter = 40 /* numero massimo di iterazioni */
max_mod = 4 /* distanza del modulo */
minx = -2 /* finestra di partenza */
maxx = 1.25
miny = -1.25
maxy = 1.25
scala= 1 /* fattore di scala: inizialmente 1:1 */
for {
draw(minx,maxx,miny,maxy,max_iter,max_mod,scala,xa,xb, dc)
filename := fmt.Sprintf("mandelbrot-picture-%d.png", k)
dc.SavePNG(filename)
k++
scala = scala / vzoom
max_iter = max_iter + q
}
}Le figure successive sono un campione della sequenza di immagini prodotta



Ora passiamo ad una webapp!
L’elenco di tutte numerose librerie è facilmente consultabile alla pagina :
https://github.com/avelino/awesome-go/blob/main/readme.md
In relazione agli obiettivi generali di questa mia esperienza di studio ho testato le librerie a disposizione per lo sviluppo di applicazioni web.
Al primo approccio ho subito riscontrato nelle ricerche fatte su internet che la libreria standard di GoLang è diffusamente utilizzata perchè supporta la creazione di applicazioni web, la gestione delle richieste HTTP e il servizio del traffico HTTPS.
Si nota inoltre come questa permetta di implementare rapidamente tutti gli sviluppi necessari senza ricorrere a librerie o framework di terze parti.
Proprio la verifica di tali caratteristiche è l’obiettivo della selezione e test degli esempi riportati di seguito.
Infatti l’implementazione dei web server riportata nel successivo esempio è basata sull’uso del package net/http e richiede la scrittura di poche righe di codice in relazione alla complessità delle funzioni che il server deve rendere disponibili (e.g. gestione di informazioni estratte da un database).
La specificità di questo esempio (reperito sul sito https://freshman.tech/web-development-with-go/ ) consiste nell’identificare successive fasi di scrittura del codice, ognuna delle quali aggiunge funzionalità al server e fornisce contemporaneamente dettagli descrittivi. Ho trovato molto utile questo tipo di approccio a livello didattico.
Da notare che devono essere eseguite tutte le procedure riportate nel sito citato per replicare l’ambiente necessario all’esecuzione dell’esempio.
Fase 1 – “Hello World!”
Di seguito riporto il codice iniziale del file main.go
//----------------------------------------------------------------------------------
//Phase [01] - Basic server sending "Hello World" when recives a GET request
//----------------------------------------------------------------------------------
package main
import (
"net/http"
"os"
)
//w is the structure used to respond to an HTTP request (i.e. implements the Write() method
//which accepts a slice of bytes and write the data to the connection as part of an HTTP response
//r is the request provided by the client; to be used later on
func indexHandler(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("<h1>Hello World!</h1>"))
}
func main() {
//if PORT environment variable is set, use it
//otherwire use the default port 8080
port := os.Getenv("PORT")
if port == "" {
port = "3000"
}
//create a http request multiplexer (i.e. match the URL of incoming requests
//against a list of pre-registered patterns and calls only the associated handler)
mux := http.NewServeMux()
//calls only for these the associated handler
mux.HandleFunc("/", indexHandler)
//starts the server on the defined port
http.ListenAndServe(":"+port, mux)
}
Questo file deve essere compilato tramite il comando :
$ go buildper poi essere lanciato dal comando :
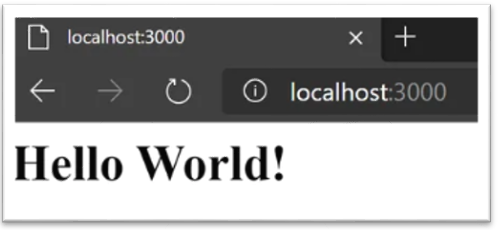
$ ./news-demo-starter-filesSuccessivamente accedendo da browser al sito http://localhost:3000/ dovrebbe apparire la pagina iniziale contenente il testo “Hello World!”.
Fase 2 – Variabili d’ambiente
Secondo le “best practices linux” è necessario generare un file contenente le variabili d’ambiente che vengono lette dall’applicativo alla sua partenza.
In particolare è necessario editare il file .env inserendo la definizione della porta da utilizzare.
PORT=3000Successivamente va installato e eseguito il package godotenv eseguendo il comando :
$ go get github.com/joho/godotenvdi conseguenza va aggiornato il file main.go come segue :
//----------------------------------------------------------------------------------
//Phase [02] - Environmental variables usage
//----------------------------------------------------------------------------------
package main
//Added import of packages "log" and "github.com/joho/godotenv"
import (
"log"
"net/http"
"os"
"github.com/joho/godotenv"
)
func indexHandler(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("<h1>Hello World!</h1>"))
}
func main() {
//Load() method reads .env files and loads environmental variables
err := godotenv.Load()
if err != nil {
log.Println("Error loading .env file")
}
port := os.Getenv("PORT")
if port == "" {
port = "3000"
}
mux := http.NewServeMux()
mux.HandleFunc("/", indexHandler)
http.ListenAndServe(":"+port, mux)
}Verificare la disponibilità della pagina “Hello World!” dopo le modifiche apportate.
Fase 3 – Uso dei template in Go
I template, come per tanti altri linguaggi, costituiscono un modo semplice per personalizzare in modo riusabile ogni applicazione web.
In questa fase verrà realizzata una barra di navigazione per tutto il sito senza dover replicare il codice; per fare questo utilizziamo il package html/template , modificando il file main.go come segue:
//----------------------------------------------------------------------------------
//Phase [03] - Template usage
//----------------------------------------------------------------------------------
package main
//Added import of package "html/template"
import (
"html/template"
"log"
"net/http"
"os"
"github.com/joho/godotenv"
)
//tpl (package variable) points to the provided package definition parsing the index.html
//ParseFiles rises panic code if an error is obtained parsing the file
var tpl = template.Must(template.ParseFiles("index.html"))
func indexHandler(w http.ResponseWriter, r *http.Request) {
//nil is passed as second argoment since no data are to be passed to the template at this time
tpl.Execute(w, nil)
}
func main() {
err := godotenv.Load()
if err != nil {
log.Println("Error loading .env file")
}
port := os.Getenv("PORT")
if port == "" {
port = "3000"
}
mux := http.NewServeMux()
mux.HandleFunc("/", indexHandler)
http.ListenAndServe(":"+port, mux)
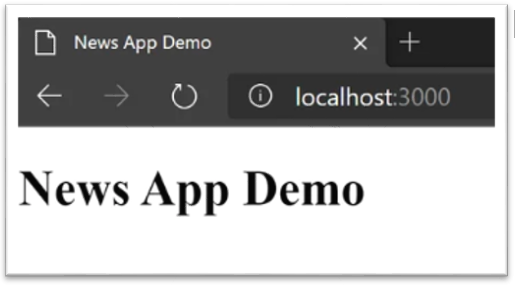
}Ora è necessario stoppare l’eseguibile precedentemente lanciato e lanciarlo nuovamente dopo aver ricompilato il file main.go; aggiornando il browser verrà presentata la pagina “News App Demo”.
Fase 4 – Restart automatico del server
Utilizzo il package Air che esegue il restart automatico del server quando vengono eseguite modifiche nel codice evitando quindi ogni noiosa attività di shutdown e riavvio del server stesso.
L’installazione del package è esguita tramite il comando :
$ go install github.com/cosmtrek/air@latestIl package va poi lanciato in backround all’inizio di ogni sessione di lavoro tramite il comando
$ air &Fase 5 – Aggiunta di una barra di navigazione
Il layout delle nostre pagine web è definito nel file index.html che va modificato come segue:
<!DOCTYPE html>
<!-- ---------------------------------------------------------------------------- -->
<!-- Phase [05] - Add navigation bar -->
<!-- ---------------------------------------------------------------------------- -->
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>News App Demo</title>
<link rel="stylesheet" href="/assets/style.css" />
</head>
<body>
<!-- Navigation bar begin -->
<main>
<header>
<a class="logo" href="/">News Demo</a>
<form action="/search" method="GET">
<input
autofocus
class="search-input"
value=""
placeholder="Enter a news topic"
type="search"
name="q"
/>
</form>
<a
href="https://github.com/freshman-tech/news"
class="button github-button"
>View on GitHub</a
>
</header>
</main>
<!-- Navigation bar end -->
</body>
</html>A questo punto basta aggiornare la pagina del browser per vedere le modifiche aggiunte.
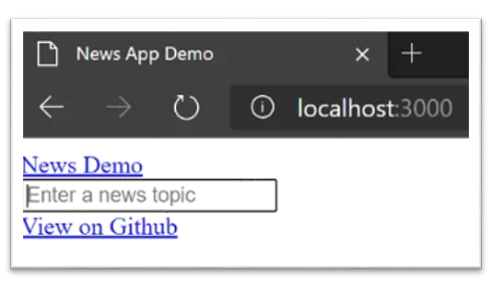
Fase 6 – Aggiunta di elementi grafici
Visivamente la barra di navigazione ha un aspetto minimale : l’aggiunta di elementi grafici può fornirle un aspetto più moderno.
Il codice completo del file main.go risulta quindi essere :
//----------------------------------------------------------------------------------
//Phase [06] - Add graphic features
//----------------------------------------------------------------------------------
package main
import (
"html/template"
"log"
"net/http"
"os"
"github.com/joho/godotenv"
)
var tpl = template.Must(template.ParseFiles("index.html"))
func indexHandler(w http.ResponseWriter, r *http.Request) {
tpl.Execute(w, nil)
}
func main() {
err := godotenv.Load()
if err != nil {
log.Println("Error loading .env file")
}
port := os.Getenv("PORT")
if port == "" {
port = "3000"
}
//Instantiate a file server bypassing the allocation directory for static files containing the
//graphic features (i.e. /assets directory)
fs := http.FileServer(http.Dir("assets"))
mux := http.NewServeMux()
//Request the router to use th file server for all paths beginning with /assets/ prefix
mux.Handle("/assets/", http.StripPrefix("/assets/", fs))
mux.HandleFunc("/", indexHandler)
http.ListenAndServe(":"+port, mux)
}Una volta riaggornata la pagina sul browser, questa presenterà gli effetti grafici introdotti .
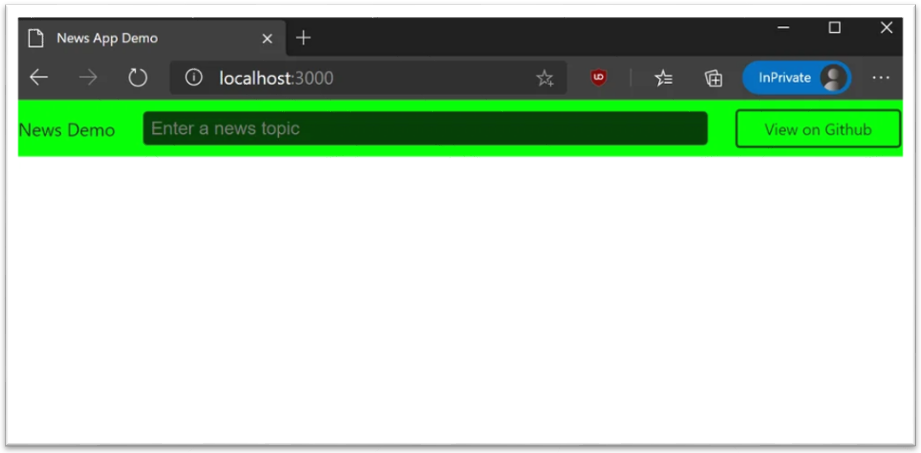
Nel sito di riferimento di questo esempio sono presenti ulteriori attività necessarie alla gestione del database delle informazioni da presentare sulla web page; tali attività, per nulla banali, esulano dagli obiettivi del mio studio.
Lesson learned
Come si può notare dallo svolgimento dell’esempio, oltre alla conoscenza generale di GoLang, è indispensabile avere familiarità con i costrutti HTML necessaria alla generazione dei contenuti delle pagine web.
Inoltre, nell’esperienza raccolta durante la fase di ricerca su internet, ho incontrato molti esempi di creazione di web server, citati dagli autori come “semplici” ma che richiedevano comunque la conoscenza di altri strumenti/linguaggi.
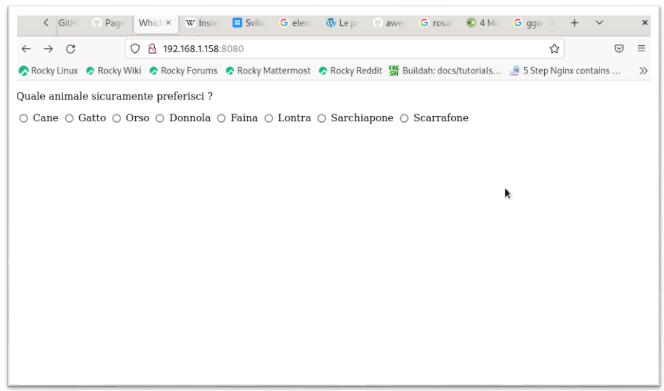
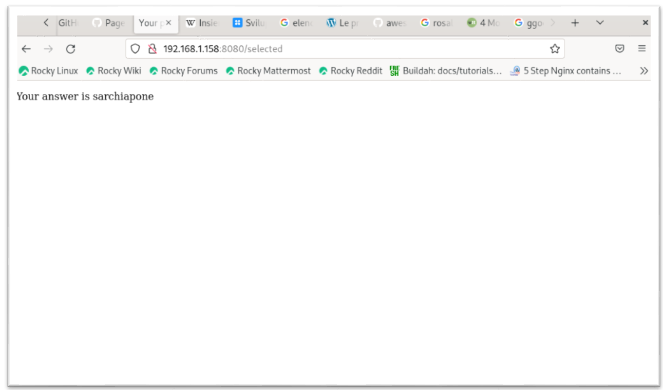
Ad esempio nel sito https://wwww.blog.scottlogic.com/2017/02/28/building-a-web-app-with-go.html dal titolo “Creating my first web application with Go”, viene descritto come generare una web app che nell’ordine :
- presenta all’utente alcuni RadioButton su una pagina html
- premette all’utente di eseguire una scelta
- fornisce una risposta relativa alla scelta eseguita
Per questo scopo viene realizzato un html javascript che invoca :
- google API AJAX
- CSS (Cascading Style Sheets)
- HTML tag come ad esempio {{with}} e {{end}}
Per completezza le due figure che seguono rappresentano nell’ordine la prima pagina del web server e quella successiva alla selezione dell’utente.
Ambiente controllo e distribuzione app
A questo punto dello studio è emersa la necessità di poter condividere l’esperienza raggiunta condividendo tra più utenti gli artefatti prodotti e gli strumenti utilizzati. Il problema più comune nella condivisione è che spesso un software funziona su un computer ma non funziona su sistemi di altri a causa della diversità dell’ambiente.
Cercando su Internet la disponibilità di logiche strutturali che risolvano questo tipo di problema e che abbiano anche caratteristiche di semplicità d’uso, basso consumo di risorse hardware e sicurezza di trasmissione di dati, ho trovato molto rispondente il concetto di container.
La prima definizione trovata in Internet di container Linux (o anche soltanto container) è quella di processi informatici residenti in ambienti isolabili, minimali e facilmente distribuibili, aventi l’obiettivo di semplificare i processi di deployment di applicazioni software, come identificati nella figura che segue.
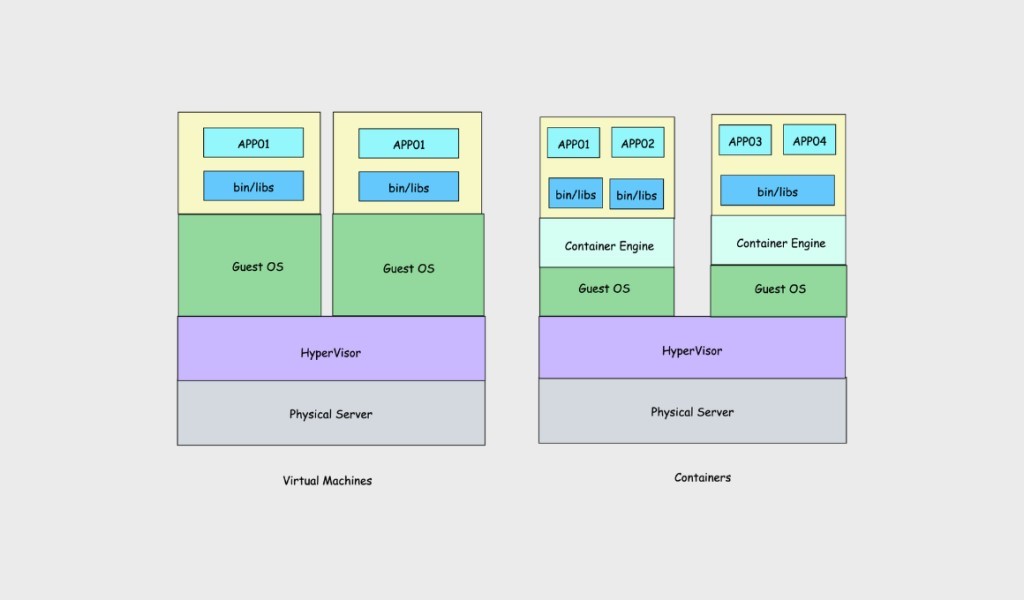
Da considerare che, nel passato, un tipico ambiente virtualizzato era composto da una o più macchine virtuali che venivano eseguite su uno o più server fisici, tramite strumenti di tipi HyperVisor come ad esempio Hyper-V.
Viceversa i container sono eseguiti direttamente dal kernel del sistema operativo (i.e. definiti come OS-level virtualization).
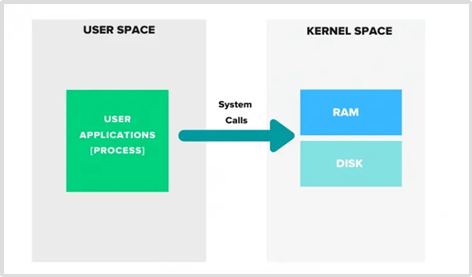
La precedente figura identifica la logica di due concetti tipici di Linux :
- User-Space: ospita tutto il codice necessario all’esecuzione di programmi utente (i.e. applicazioni, processi). Ad esempio ogni azione richiesta da un programma, come creare un file, stimola una richiesta esecutiva dello User-Space verso il Kernel-Space
- Kernel-Space: è il cuore del sistema operativo che gestisce tutte le risorse hardware.
Quindi ogni processo riesce ad interagire direttamente con il Kernel-Space con il livello di isolamento associato alla tipologia delle istruzioni eseguite dal processo stesso.
L’utilizzo di container provvede ad isolare un processo tramite l’uso dei soli specifici file di configurazione necessari alla sua attivazione.
Il metodo di approccio dei container è quello di generare un ambiente isolato per il processo per garantire un alto livello di sicurezza, consistenza e portabilità, quand’anche eseguito su diversi sistemi.
La figura successiva illustra i concetti esposti.
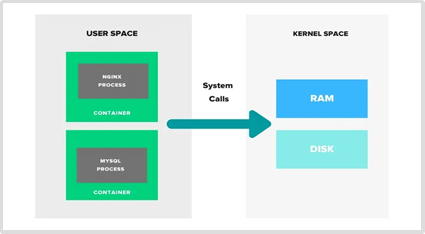
Più in generale, l’attivazione di un processo all’interno di un container richiede l’utilizzazione di più processi e servizi destinati a garantire tutte le funzioni proprie del container; ciò avviene in maniera automatica e trasparente all’utente, a totale carico del container stesso.
Altre importanti caratteristiche dei container sono:
- Ogni container dispone del proprio isolato User-Space: ciò rende possibile attivare più container ospitati sul medesimo Host
- Non è necessario installare un intero OS all’interno di un container ( i.e. diversamente dall VM)
- Ogni container deve ospitare solo tutti I file necessari relativi alla specifica distribuzione da utilizzare, ma non il kernel: viene utilizzato direttamente I kernel condiviso dall’host.
Quindi è possibile installare su un singolo host più container basati su distribuzioni diverse.
- All’attivazione un container esegue un singolo processo (main process) che è responsabile di gestire eventuali processi derivati, se necessario; ciò garantisce l’isolamento e la stabilità del container stesso.
- L’isolamento del container è implementato attraverso l’uso di due funzioni chiave del kernel Linux:
- Name-Space.
- Control Groups (Cgroups).
che gestiscono l’insieme di CPU, memoria, indirizzi IP e mount point allocati del container stesso.
Nello specifico Linux permette di utilizzare le direttive di Control Group per settare limiti espliciti all’uso di CPU, memoria e servizi.
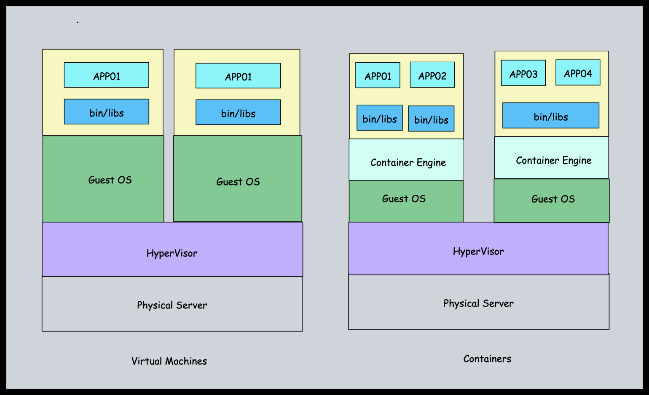
In sintesi, la figura che segue schematizza le pricipali differenze tra container e VM.
Presa la decisione di utilizzare i container, sono passato alla selezione degli strumenti disponibili per implementare e gestire quest’ultimi.
Utilizzando sempre Internet come fonte, ho trovato che lo strumento più diffuso per la gestione dei container è Docker e l’ho analizzato.
Docker – Primo strumento
Dal punto di vista architetturale, Docker è nativamente disponibile in ambiente GNU/Linux.
Tuttavia, per favorire le attività di sviluppo, è stata generata una distribuzione eseguibile direttamente sulle workstation, con OS macOS e Windows.
È quindi chiaro che, su piattaforme non Linux, è necessario installare una VM Linux atta ad eseguire un kernel Linux al quale si appoggia l’engine Docker.
Inoltre Docker utilizza un’architettura client-server dove il Docker Deamon (locale a Docker Client o su nodo remoto) ha il compito totale di eseguire e distribuire tutti i docker container.
Senza scendere in ulteriori dettagli architetturali/implementativi come la gestione di immagini, volumi, plugin, registri di configurazione, Docker API di interconnessione di Docker Client-Sever, o package di installazione del Docker Desktop, devo chiarire che l’impressione ricevuta dall’analisi dei documenti consultati non è stata del tutto positiva.
In particolare la presenza obbligatoria di una macchina virtuale Linux per utilizzare Docker su di una piattaforma Windows, a mio parere, fa preferire l’utilizzo di una verisone Linux nativa.
In aggiunta, la presenza di una architettura client-server fa supporre che questo strumento possegga un livello di complessità superiore a quello gestibile da un utente poco esperto.
Per questi motivi ho deciso di utilizzare una piattaforma nativa Linux ( anche per lo sviluppo di applicazioni sviluppate in GoLang) e di estendere la ricerca a strumenti di gestione di container preferibilmente anch’essi nativi Linux e che non utilizzino un’architettura client-server.
I prossimi paragrafi contengono, nell’ordine, la descrizione della distribuzione Linux selezionata e di uno strumento alternativo a Docker corredato di applicazioni satellite che ne facilitano l’utilizzazione.
Sostituzione distribuzione Linux – Rocky
La società CentOS nel tempo rilasciava gratuitamente piattaforme di sviluppo per le future versioni di Red Hat Enterprise Linux (RHEL) a scopo di debugging, ma attualmente questa collaborazione è interrotta.
Volendo utilizzare una distribuzione UpToDate ho scelto la distribuzione Linux Rocky 9.2, perché anche questa è generata e distribuita in modo gratuito da una società no-profit, avente compatibilità binaria con la distribuzione RHEL e basata sulla stessa filosofia di CentOS.
Il progetto Rocky ha l’obiettivo di fornire un sistema operativo di tipo enterprise capace di uso frequente e intensivo in ambiente di ufficio, commerciale o industriale (i.e. production grade).
Podman – Alternativa efficace a Docker
Il prodotto selezionato alternativo a Docker è Podman che implementa tutte le funzionalità descritte nel paragrafo che descrive i container.
Le caratterisctiche di Podman che ne hanno indirizzato la selezione sono le seguenti:
- il pacchetto Podman viene distribuito e automaticamente installato nella distrubuzione Rocky 9.2 ; essendo Rocky una distribuzione di livello production grade, la presenza di Podman indica che è stato stimato essere un prodotto sicuro e performante
- capacità di gestire i container senza i privilegi di root, il che aggiunge un ulteriore livello di sicurezza
- non possiede un’architettura client-server, quindi non necessita dell’utilizzo di un deamon
- ogni utente Podman ha capacità di modificare i soli container da lui generati e quindi non è in grado di modificare container di altri utenti
- disponibilità di strumenti (Buildah, Skopeo) che supportano e talvolta semplificano la gestione e pubblicazione di container e immagini.
Installazione
Molto vantaggiosamente Podman è già installato dalla distribuzione Rocky9.2 .
Analisi generale
Prima di procedere all’illustrazione delle attività di uso di Podman , ritengo necessario sintetizzarne in anticipo glossario, funzionalità e obiettivi.
“Podman” è la contrazione di “POD manager”, dove i pod sono gruppi di container che vengono eseguiti insieme e condividono le stesse risorse con la possibilità di comunicare/interagire tra loro.
Di conseguenza i POD svolgono funzione di infrastruttura nella gestione degli elementi basilari di Podman che sono container e immagini.
Per chiarire subito quali siano le differenze tra questi due elementi è possibile usare un’analogia con il linguaggio object oriented dove l’immagine può essere assimilata ad una classe, mentre il container può essere visto come un’istanza della classe.
Quindi un’immagine è la raccolta (statica e immutabile) dei soli elementi del sistema operativo e delle librerie applicative necessarie all’esecuzione della funzione che gli è richiesta.
Il container invece consiste nell’esecuzione del codice di un’immagine in uno specifico contesto (e.g. associazione al container della specifica porta IP su cui scambiare informazioni, gestione del proprio spazio di archiviazione).
Per facilitare chiunque voglia utilizzare container, la società che ha sviluppato podman (redhat) ha provveduto a raccogliere una serie di immagini di interesse generale e le ha fornite automaticamente all’atto dell’installazione in due registri consolidati : quay.io e docker.io .
L’utente è comunque sempre libero di creare e utilizzare le proprie immagini.
A questo punto l’utente può eseguire più container contemporaneamente, a partire da qualsiasi immagine disponibile, in maniera isolata l’uno dall’altro (se non lanciati nello stesso POD) e tutti isolati dalla macchina host su cui sono in esecuzione.
E’ importante notare che al termine del lavoro di un container l’utente può salvare le modifiche apportate runtime creando una nuova immagine da inserire nel registro delle immagini da poter condividere con altri utenti.
Primo uso – regole di base
Come già accennato, Podman può essere utilizzato da un qualsiasi utente Linux senza che egli abbia i privilegi di root (i.e. rootless); questo aspetto però si scontra con la necessità di possedere privilegi superiori quando si cerca di gestire immagini e container.
Per risolvere questo aspetto Podman mette a disposizione il comando unshare, che in sostanza lancia una nuova shell a cui sono applicati UID 0 e GID 0 ( User ID e Group ID) senza necessità di modificare temporaneamente il tipo di utente , cioè senza anteporre il comando sudo ad ogni comando Podman interessato.
Occorre sottolineare però che, avendo creato una nuova shell, tutte le variabili d’ambiente dichiarate al suo interno non saranno più disponibili una volta terminata la sessione generata dal comando unshare; infatti durante lo studio degli esempi trovati su internet, non sempre la descrizione dell’uso di unshare è stata consistente, per cui l’esecuzione degli esempi stessi non arrivava a buon fine.
Sempre a proposito dell’utilizzo rootfull o rootless di Podman, ho consultato l’articolo trovato nel sito
hhtps://www.redhat.com/sysadmin/rootless-podman-makes-sense, che da una parte fornisce abbondanti dettagli sul funzionamento del comando unshare, dall’altra riporta il fatto che alcuni utenti continuano ad utilizzare la modalità rootfull ma allo stesso tempo disabilitano la funzione SELinux. Ho intenzione di affrontare questo argomento una volta raccolte maggiori informazioni sull’uso complessivo di Podman. Suggerisco di prendere a riguardo una decisione e di manternerla costante.
Esempi uso Podman
Come primo utilizzo delle funzionalità di base, tra le procedure trovate molto simili tra loro ho selezionato da internet quello che si presentava più lineare per giungere subito ad avere un risultato pratico evidente:
Getting Started with Podman (Docker Alternative) on Rocky Linux (howtoforge.com)
L’obiettivo è installare un web server ad alte prestazioni : nginx.
Il primo passo consiste nel cercare un’immagine disponibile negli hub ( registri ) in rete con il comando
$ podman search nginx --limit 3l’opzione –limit n riduce ad n i risultati forniti per ogni registro.
Viene visualizzata una lista delle possibili versioni dell’immagine cercata e una breve descrizione.
Ho scelto di scaricare l’immagine di nginx appartenente alla distribuzione Linux Alpine tramite il comando
$ podman pull nginx:alpineQualora esistessero più immagini corrispondenti in diversi registri è richiesto selezionarne una come mostrato di seguito.
? Please select an image:
registry.fedoraproject.org/nginx:alpine
registry.access.redhat.com/nginx:alpine
registry.centos.org/nginx:alpine
? docker.io/library/nginx:alpineAl termine del comando è possibile verificare l’esito del download digitando:
$ podman images che restituisce la lista delle immagini presenti sull’host.
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/library/nginx alpine b46db85084b8 3 days ago 24.7 MB
docker.io/library/hello-world latest feb5d9fea6a5 7 weeks ago 19.9 kBE’ possibile eseguire il container, basato sull’immagine nginx:alpine tramite il comando :
$ podman run -it --rm -d -p 8080:80 --name web nginx:alpineQueste opzioni risultano frequentemente utilizzate e hanno i seguenti significati:
- -it permette di scambiare input/output con Podman
- –rm rimuove automaticamente il container quando viene terminata l’esecuzione
- -d esegue il container in background e in modo non interattivo
- -p espone una porta per l’applicazione all’interno del container (80) mappata su una porta dell’host (8080)
- –name associa un nome al container
A questo punto è possibile aprire un browser sull’indirizzo IP della macchina Rocky Linux alla porta mappata 8080 che visualizzerà la pagina di default ( index.html ) del container web.
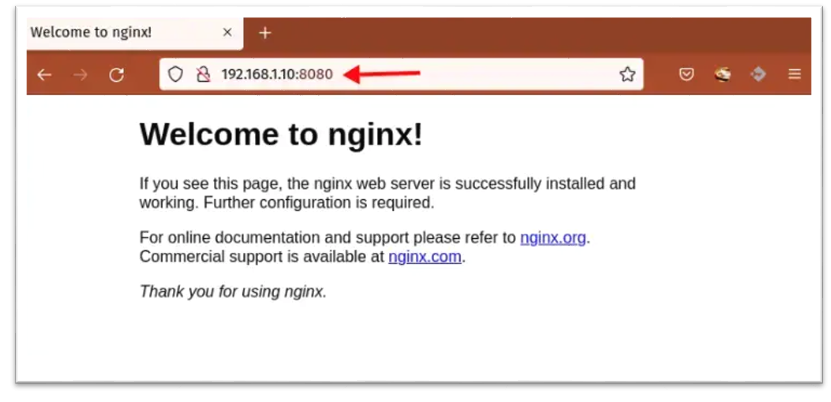
Il container viene stoppato (e contestualmente eliminato per via dell’opzione –rm nel comando
podman run) tramite il comando
$ podman stop webHo creato poi in una cartella separata una versione del file index.html modificata nel modo seguente
$ mkdir -p ~/data/
$ nano ~/data/inde.html<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Welcome to Container Nginx</title>
</head>
<body>
<h2>Hello from Nginx container - Managed with Podman</h2>
</body>
</html>Infine ho eseguito un nuovo container, dotato di un volume personalizzato tramite il comando
$ podman run -it --rm -d -p 8080:80 --name web -v ~/data:/usr/share/nginx/html nginx:alpinedove il primo parametro dell’opzione -v indica il percorso assoluto del file system locale, contenente la modifica del file index.html, il secondo contiene il percorso assoluto della cartella del file system all’interno del container destinato a contenere il file modificato.
Aprendo nuovamente il browser allo stesso indirizzo, viene visualizzata la pagina di default di nginx modificata

Buildah – Ampliamento/semplificazione di Podman
Nella continuazione dello studio dei container OCI (Open Container Initiative), gestiti da Docker e Podman, sono passato ad analizzare una sorta di alternativa “user friendly” : Buildah.
Installazione
Molto vantaggiosamente Buildah è già installato dalla distribuzione Rocky9.2 .
Analisi generale
In termini estremamente sintetici, le funzioni di base di gestione di container e immagini sono identiche tra Podman e Buildah (al netto di differenze della composizione dei comandi analoghi).
Tuttavia sono stato colpito dalla filosofia nativa con cui è stato ideato e prodotto Buildah che è basata su 3 obiettivi principali :
- semplificare la creazione delle immagini
- rendere performanti i container in termini di riduzione di occupazione di memoria e risorse di calcolo
- rendere più agili le attività di conservazione e distribuzione di container ed immagini
Questi obiettivi si traducono nelle specifiche capacità di Buildah di :
- creare immagini senza necessità di utilizzare un Dockerfile ( utilizzato da Podman) ossia di un documento di testo contenente tutti comandi necesari per assemblare l’immagine
- creare immagini vuote nelle quali introdurre le sole componenti necessarie
- non includere strumenti di compilazione nell’immagine in modo da ridurre le dimensioni e incrementare la sicurezza
- esaminare, verificare e modificare immagini
- inviare rapidamente immagini da uno storage locale ad un registro o repository privato
- utilizzare i contenuti aggiornati di un file system root di un container come punto di partenza per una nuova immagine
Ho trovato molto significativo l’esempio che riporto di seguito relativo a come Buildah crea immagini da scratch.
Dovendo produrre un’immagine di una applicazione Java, in Podman potrebbe essere necessario l’utilizzazione del compilatore Java e altri tool. In fase di utilizzo è necessario avere a disposizione solo la componente runtime e package prodotto ( riferimento al sito https://developers.redhat.com/blog/2019/02/21/podman-and-buildah-for-docker-users).
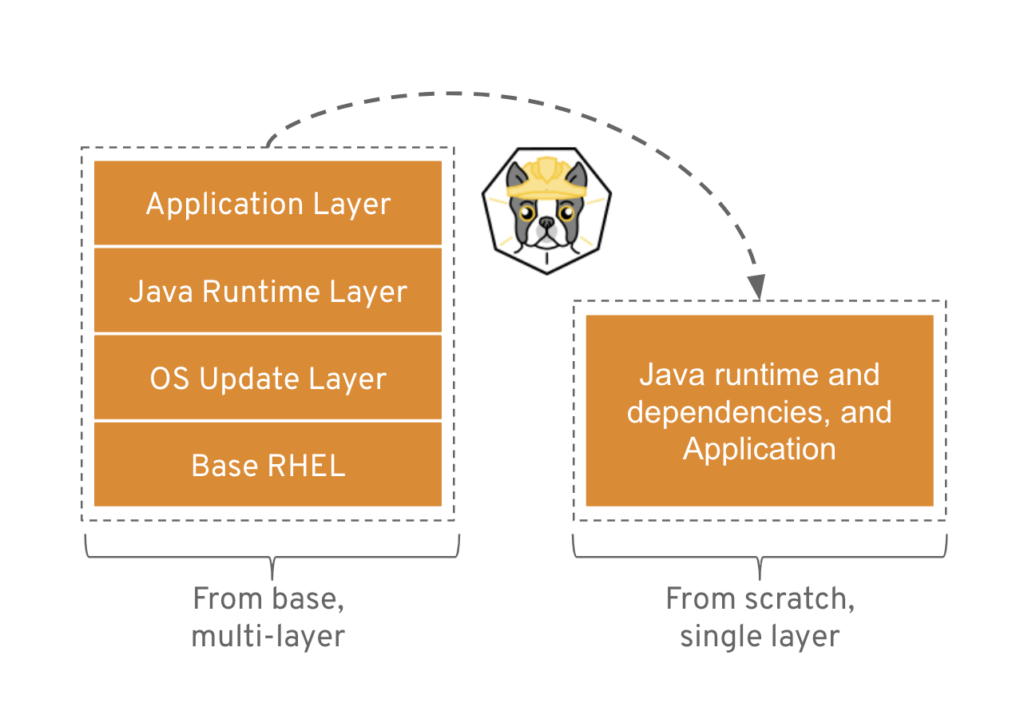
Volendo aggiungere una mia opinione, la documentazione di Buildah, ideato ed usato da RedHat, risulta avere una maggiore estensione e precisione di dettagli.
Esempio uso Buildah
L’esempio proposto è quello di creare un’immagine partendo da scratch.
Ho creato un container a partire da un’immagine vuota tramite il comando
$ newcontainer=$(buildah from scratch)Tale contaniner è anch’esso vuoto, come verificabile dal comando
$ buildah containersche produce un output simile al seguente
CONTAINER ID BUILDER IMAGE ID IMAGE NAME CONTAINER NAME
ac8fa6be0f0a * scratch working-containerche indica che è stato prodotto un container dal nome working-container a partire da un’immagine “scratch”.
Eseguendo il comando
$ buildah imagesnon viene visualizzata alcuna immagine.
Il container creato è quindi completamente vuoto e non è possibile interagire direttamente con esso.
Per poter fare ciò è necessario lanciare il comando di mount come segue
$ scratchmounrt=$(buildah mount newcontainer)che permette di raggiungere direttamente la root del file system del container.
Ora è possibile installare package nel container o semplicemente copiare al suo interno file presenti sul file system host. Per installare qualunque pacchetto applicativo è necessario iniziare con l’installazione del bash e delle coreutils, come riportato nel successivo comando
$ dnf install --installroot $scratchmnt --release 9 bash coreutils --setopt install_weak_deps=false -ydove il valore associato all’opzione –release è la release della distribuzione Linux del sistema host.
Il seguente comando permette di lanciare una shell bash all’interno del container
$ buildah run $newcontainer bash
bash-4.4# cd /usr/bin
bash-4.4# ls
bash-4.4# exitCreando e rendendo eseguibile nel sistema host un semplice bash script
#!/bin/bash
#Filename : prova.sh
for i in `seq 1 5`;
do
echo "Esecuzione numero [" $i "] all'interno del nuovo container"
done$ chmod +x prova.shSuccessivamente ho prima copiato lo script all’interno del container e in seguito richiesto che lo script venisse eseguito all’attivazione del container, infine ho mandato in esecuzione il container .
$ buildah copy $newcontainer ./runecho.sh /usr/bin
$ buildah config --cmd /usr/bin/runecho.sh $newcontainer
$ buildah run $newcontainerL’output generato è riportato di seguito
Esecuzione numero [ 1 ] all'interno del nuovo container
Esecuzione numero [ 2 ] all'interno del nuovo container
Esecuzione numero [ 3 ] all'interno del nuovo container
Esecuzione numero [ 4 ] all'interno del nuovo container
Esecuzione numero [ 5 ] all'interno del nuovo containerSupponendo di aver concluso le attività col container è necessario fare l’unmount del container
$ buildah unmount $newcontainerA questo punto con l’attuale configurazione del container è possibile generre un’immagine denominata rocky-prova-bash
$ buildah commit $newcontainer rocky-prova-bashPer verificare l’avvenuta creazione dell’immagine ho lanciato il comando
$ buildah imagesE’ ora possibile cancellare il container
$ buildah rm $newcontainerPer poi successivamente, in caso di necessità, rigenerare il container tramite il comando
$ newcontainer=$(buildah from rocky-prova-bash)Skopeo – Gestione “industriale” dei containder
Ovviamente il contesto di questo studio ha coinvolto la gestione di un numero molto piccolo di immagini e container.
Pensando in un concreto contesto lavorativo è facile dedurre come questo numero aumenti e come esistano numerose relazioni da memorizzare tra immagini e/o container in modo tale da essere sempre in grado di fornire agli utenti finali proprio gli strumenti “containerizzati” di cui hanno hanno necessità.
D’altra parte l’efficienza della produzione e distribuzione degli oggetti containerizzati richiede la disponibilità di un ambiente di lavoro massimamente “user friendly”.
Questo obiettivo è raggiungibile tramite l’uso coordinato di Podman, Buildah e Skopeo ognuno dei quali elabora in modo specifico container OCI.
In poche parole, Buildah realizza i container, Podman li esegue e Skopeo li trasporta.
Analisi generale
Le caratteristiche fondamentali di Skopeo (open source) consistono in :
- non utilizzare alcun di un container demo.
- permettere l’ispezione completa di tutti i metadati di immagini residenti su un registro remoto senza richiedere il download locale dell’intera immagine
- essere in grado di elaborare immagini di formato OCI e Docker
- permettere di eliminare immagini da un repository
- sincronizzare un repository esterno di immagini con un registro interno
- gestire in sicurezza il deployment di immagini su reti disconnesse
- permettere di eseguire, con specifiche configurazioni, copie tra registri, tra registri e file ( per backup) e tra file e registri ( per ripristino)
Anche Skopeo, come Buildah, è stato ideato ed utilizzato da RedHat e questo è garanzia della bontà dell’integrazione di questi prodotti anche in futuro.
Installazione
Skopeo è presente nella distribuzione Rocky9.2 ma non immediatamente installato; è quindi richiesta l’ installazione manuale:
$ sudo dnf -y install skopeoEsempi uso skopeo
Come prima verifica ho ispezionato l’immagine remota nginx, utilizzata frequentemente nei test eseguiti nel corso dello studio, senza richedere il report sui tag poichè molto numerosi
$ sudo skopeo inspect --no-tags docker://docker.io/library/nginx Il comando produce la lista completa dei metadati dell’immagine
{
"Name": "docker.io/library/nginx",
"Digest": "sha256:104c7c5c54f2685f0f46f3be607ce60da7085da3eaa5ad22d3d9f01594295e9c",
"RepoTags": [],
"Created": "2023-08-16T09:50:55.765544033Z",
"DockerVersion": "20.10.23",
"Labels": {
"maintainer": "NGINX Docker Maintainers \u003cdocker-maint@nginx.com\u003e"
},
"Architecture": "amd64",
"Os": "linux",
"Layers": [
"sha256:52d2b7f179e32b4cbd579ee3c4958027988f9a8274850ab0c7c24661e3adaac5",
"sha256:fd9f026c631046113bd492f69761c3ba6042c791c35a60e7c7f3b8f254592daa",
"sha256:055fa98b43638b67d10c58d41094d99c8696cc34b7a960c7a0cc5d9d152d12b3",
"sha256:96576293dd2954ff84251aa0455687c8643358ba1b190ea1818f56b41884bdbd",
"sha256:a7c4092be9044bd4eef78f27c95785ef3a9f345d01fd4512bc94ddaaefc359f4",
"sha256:e3b6889c89547ec9ba653ab44ed32a99370940d51df956968c0d578dd61ab665",
"sha256:da761d9a302b21dc50767b67d46f737f5072fb4490c525b4a7ae6f18e1dbbf75"
],
"LayersData": [
{
"MIMEType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"Digest": "sha256:52d2b7f179e32b4cbd579ee3c4958027988f9a8274850ab0c7c24661e3adaac5",
"Size": 29124563,
"Annotations": null
},
{
"MIMEType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"Digest": "sha256:fd9f026c631046113bd492f69761c3ba6042c791c35a60e7c7f3b8f254592daa",
"Size": 41338560,
"Annotations": null
},
{
"MIMEType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"Digest": "sha256:055fa98b43638b67d10c58d41094d99c8696cc34b7a960c7a0cc5d9d152d12b3",
"Size": 628,
"Annotations": null
},
{
"MIMEType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"Digest": "sha256:96576293dd2954ff84251aa0455687c8643358ba1b190ea1818f56b41884bdbd",
"Size": 958,
"Annotations": null
},
{
"MIMEType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"Digest": "sha256:a7c4092be9044bd4eef78f27c95785ef3a9f345d01fd4512bc94ddaaefc359f4",
"Size": 371,
"Annotations": null
},
{
"MIMEType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"Digest": "sha256:e3b6889c89547ec9ba653ab44ed32a99370940d51df956968c0d578dd61ab665",
"Size": 1214,
"Annotations": null
},
{
"MIMEType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"Digest": "sha256:da761d9a302b21dc50767b67d46f737f5072fb4490c525b4a7ae6f18e1dbbf75",
"Size": 1405,
"Annotations": null
}
],
"Env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"NGINX_VERSION=1.25.2",
"NJS_VERSION=0.8.0",
"PKG_RELEASE=1~bookworm"
]
}Una seconda verifica consiste nell’applicazione del comando copy per copiare un’immagine da repository remoto su cartella dell’host
$ mkdir local-repository
$ cd local-repository
$ sudo skopeo copy docker://docker.io/library/nginx dir:$HOME/local-repository
Getting image source signatures
Copying blob e3b6889c8954 done
Copying blob a7c4092be904 done
Copying blob 96576293dd29 done
Copying blob 055fa98b4363 done
Copying blob 52d2b7f179e3 done
Copying blob fd9f026c6310 done
Copying blob da761d9a302b done
Copying config eea7b3dcba done
Writing manifest to image destination
Storing signaturesCome abbiamo già visto, un ambiente di lavoro completo richiede l’uso integrato di Podman, Buildah e Skopeo. Rappresentando questo studio una panoramica introduttiva su metodi e strumenti, abbiamo visto semplici esempi di funzionalità.
Vorrei anticipare che è già pianficato in futuro un approfondimento dei temi in un ambiente di complessità più rispondente a realistiche condizioni di lavoro.
Considerazioni finali
Arrivati alla fine di questo piccolo viaggio ci sono un paio di pensieri che vorrei aggiungere.
Non avendo precedenti cognizioni degli argomenti da trattare, ho iniziato questo studio dalla ricerca di informazioni in rete, che però sono risultate spesso frammentarie e di non immediata applicazione. Questa fase ha richiesto un grande impegno e una buona dose di tempo perché ho cercato di costruirmi un quadro coerente di ogni argomento, collezionando e correlando più fonti informative, e testandole di volta in volta attraverso l’esecuzione di prototipi ed esempi.
Al completamento di questo studio ho raccolto una serie di esperienze positive nell’utilizzo di Go e di tutti gli strumenti associati, che hanno messo in evidenza come questi siano versatili e di facile utilizzo.
Ho fiducia che troverete i contenuti (“salvo errori ed omissioni”, come era solito dire un vecchio professore de La Sapienza 🙂 ) non solo basicamente corretti ma anche di agevole applicazione, dato che uno dei miei obiettivi era proprio quello di proporre indicazioni di metodo utili in un’ampia gamma di attività similari.
Chiunque voglia discutere di questi argomenti è benvento, così da poter approfondire tecnicamente le tematiche trattate ma anche aspetti del processo cognitivo usato, a vantaggio di chi parte da zero come ho fatto io. 🙂
Un saluto dalla DevOpsTRibe e alla prossima!